
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- licence delete curl
- Test
- Kafka
- zip 파일 암호화
- springboot
- token filter test
- aggregation
- license delete
- analyzer test
- 900gle
- plugin
- matplotlib
- MySQL
- aggs
- 차트
- Mac
- flask
- License
- docker
- query
- sort
- TensorFlow
- Elasticsearch
- zip 암호화
- high level client
- Java
- Python
- 파이썬
- ELASTIC
- API
Archives
- Today
- Total
개발잡부
[tensorflow] word2vec 구현해보자 본문
반응형
음.. 이기 뭐지..
일단 수정해서 돌려보긴 했는데..
30라인 학습
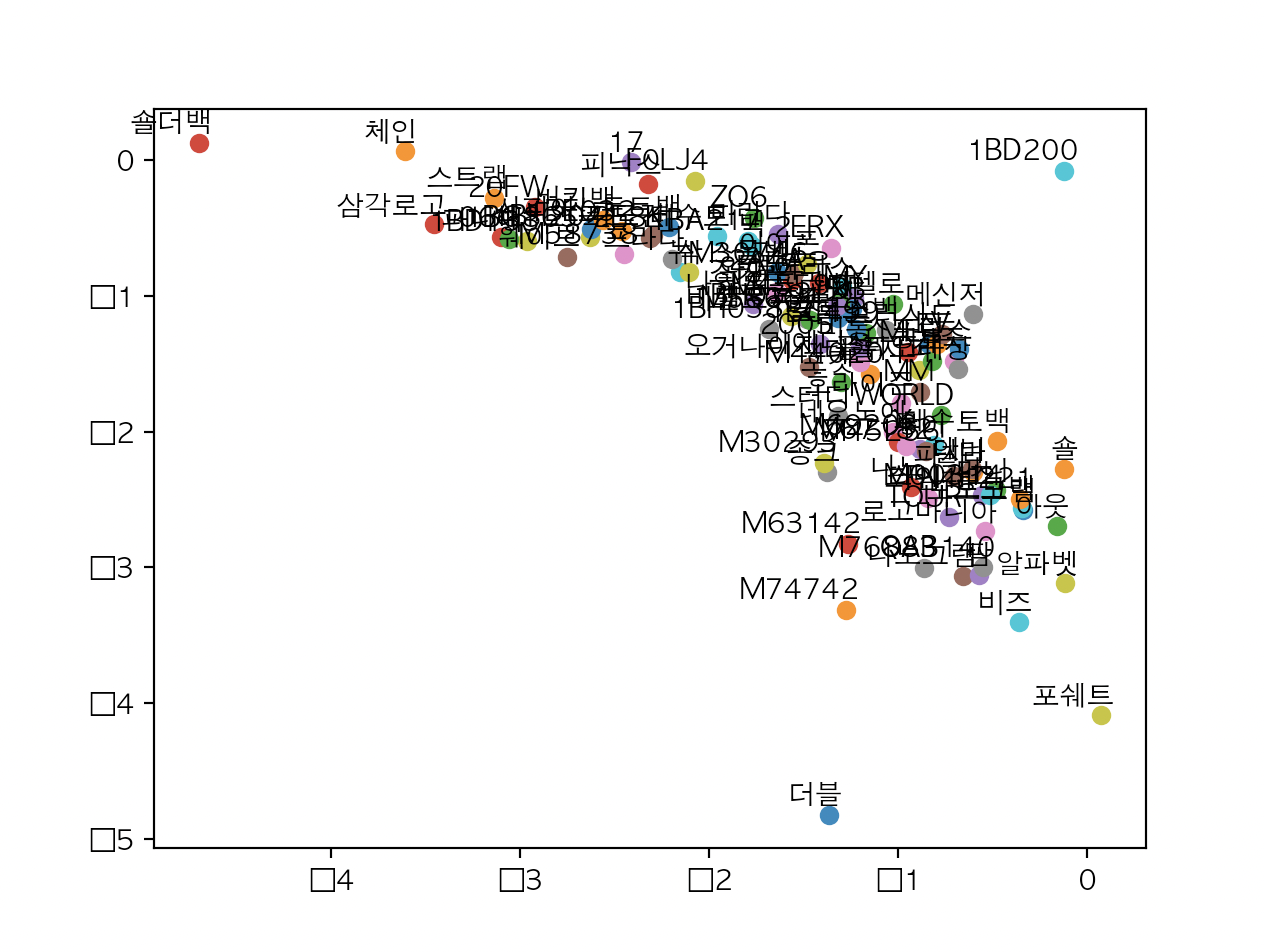
20라인 학습
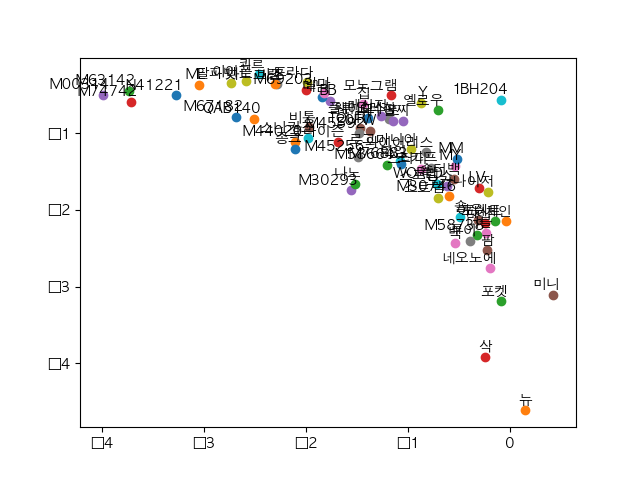
import json
import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
#한글깨짐 처리
plt.rcParams['font.family'] = 'AppleGothic'
def data():
data_array = []
DATA_FILE = "./data/products/products.json"
i = 0
with open(DATA_FILE) as data_file:
for line in data_file:
line = line.strip()
json_data = json.loads(line)
data_array.append(json_data["name"])
i += 1
if (i == 30):
break
return data_array
sentences = data()
# 문장을 전부 합친 후 공백으로 단어들을 나누고 고유한 단어들로 리스트를 만듭니다.
word_sequence = " ".join(sentences).split()
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
# 문자열로 분석하는 것 보다, 숫자로 분석하는 것이 훨씬 용이하므로
# 리스트에서 문자들의 인덱스를 뽑아서 사용하기 위해,
# 이를 표현하기 위한 연관 배열과, 단어 리스트에서 단어를 참조 할 수 있는 인덱스 배열을 만듭합니다.
word_dict = {w: i for i, w in enumerate(word_list)}
# 윈도우 사이즈를 1 로 하는 skip-gram 모델을 만듭니다.
# 예) 나 게임 만화 애니 좋다
# -> ([나, 만화], 게임), ([게임, 애니], 만화), ([만화, 좋다], 애니)
# -> (게임, 나), (게임, 만화), (만화, 게임), (만화, 애니), (애니, 만화), (애니, 좋다)
skip_grams = []
for i in range(1, len(word_sequence) - 1):
# (context, target) : ([target index - 1, target index + 1], target)
# 스킵그램을 만든 후, 저장은 단어의 고유 번호(index)로 저장합니다
target = word_dict[word_sequence[i]]
context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]]
# (target, context[0]), (target, context[1])..
for w in context:
skip_grams.append([target, w])
# skip-gram 데이터에서 무작위로 데이터를 뽑아 입력값과 출력값의 배치 데이터를 생성하는 함수
def random_batch(data, size):
random_inputs = []
random_labels = []
# np.random.choice - range(len(data)) => 정수 배열 index,
# size => 샘플링 개수
# replace => 다시 뽑을수 있는지 여부. True면 재선택 가능.
random_index = np.random.choice(range(len(data)), size, replace=False)
for i in random_index:
random_inputs.append(data[i][0]) # target
random_labels.append([data[i][1]]) # context word
return random_inputs, random_labels
#########
# 옵션 설정
######
# 학습을 반복할 횟수
training_epoch = 300
# 학습률
learning_rate = 0.1
# 한 번에 학습할 데이터의 크기
batch_size = 20
# 단어 벡터를 구성할 임베딩 차원의 크기
# 이 예제에서는 x, y 그래프로 표현하기 쉽게 2 개의 값만 출력하도록 합니다.
embedding_size = 2
# word2vec 모델을 학습시키기 위한 nce_loss 함수에서 사용하기 위한 샘플링 크기
# batch_size 보다 작아야 합니다.
num_sampled = 15
# 총 단어 갯수
voc_size = len(word_list)
#########
# 신경망 모델 구성
######
inputs = tf.placeholder(tf.int32, shape=[batch_size])
# tf.nn.nce_loss 를 사용하려면 출력값을 이렇게 [batch_size, 1] 구성해야합니다.
labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
# word2vec 모델의 결과 값인 임베딩 벡터를 저장할 변수입니다.
# 총 단어 갯수와 임베딩 갯수를 크기로 하는 두 개의 차원을 갖습니다.
embeddings = tf.Variable(tf.random_uniform([voc_size, embedding_size], -1.0, 1.0))
# 임베딩 벡터의 차원에서 학습할 입력값에 대한 행들을 뽑아옵니다.
# 예) embeddings inputs selected
# [[1, 2, 3] -> [2, 3] -> [[2, 3, 4]
# [2, 3, 4] [3, 4, 5]]
# [3, 4, 5]
# [4, 5, 6]]
selected_embed = tf.nn.embedding_lookup(embeddings, inputs)
# nce_loss 함수에서 사용할 변수들을 정의합니다.
nce_weights = tf.Variable(tf.random_uniform([voc_size, embedding_size], -1.0, 1.0))
nce_biases = tf.Variable(tf.zeros([voc_size]))
# nce_loss 함수를 직접 구현하려면 매우 복잡하지만,
# 함수를 텐서플로우가 제공하므로 그냥 tf.nn.nce_loss 함수를 사용하기만 하면 됩니다.
# nce_loss : https://shuuki4.wordpress.com/2016/01/27/word2vec-%EA%B4%80%EB%A0%A8-%EC%9D%B4%EB%A1%A0-%EC%A0%95%EB%A6%AC/
# https://excelsior-cjh.tistory.com/156
# https://korea7030.github.io/Study13/
loss = tf.reduce_mean(
tf.nn.nce_loss(nce_weights, nce_biases, labels, selected_embed, num_sampled, voc_size))
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss)
#########
# 신경망 모델 학습
######
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
for step in range(1, training_epoch + 1):
batch_inputs, batch_labels = random_batch(skip_grams, batch_size)
_, loss_val = sess.run([train_op, loss],
feed_dict={inputs: batch_inputs,
labels: batch_labels})
if step % 10 == 0:
print("loss at step ", step, ": ", loss_val)
# matplot 으로 출력하여 시각적으로 확인해보기 위해
# 임베딩 벡터의 결과 값을 계산하여 저장합니다.
# with 구문 안에서는 sess.run 대신 간단히 eval() 함수를 사용할 수 있습니다.
trained_embeddings = embeddings.eval()
#########
# 임베딩된 Word2Vec 결과 확인
# 결과는 해당 단어들이 얼마나 다른 단어와 인접해 있는지를 보여줍니다.
######
for i, label in enumerate(word_list):
x, y = trained_embeddings[i]
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2),
textcoords='offset points', ha='right', va='bottom')
plt.show()
반응형
'Python > text embeddings' 카테고리의 다른 글
| [tensorflow] word2vec 구현해보자 3 (0) | 2022.05.20 |
|---|---|
| [tensorflow] word2vec 구현해보자 2 (0) | 2022.05.20 |
| [tensorflow 2] Text embedding API를 만들어 보자 (0) | 2022.01.15 |
| [tensorflow 2] Text embedding A/B TEST - 2 (0) | 2022.01.14 |
| [tensorflow 2] Text embedding A/B TEST - 1 (0) | 2022.01.14 |
'Python/text embeddings' Related Articles
more


Comments