
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- Python
- licence delete curl
- zip 암호화
- License
- Kafka
- flask
- plugin
- API
- 파이썬
- token filter test
- ELASTIC
- 900gle
- aggregation
- MySQL
- TensorFlow
- analyzer test
- Test
- sort
- query
- docker
- license delete
- high level client
- matplotlib
- springboot
- aggs
- Java
- Mac
- 차트
- Elasticsearch
- zip 파일 암호화
Archives
- Today
- Total
개발잡부
[es] script similarity test 본문
반응형
data set 준비
900gle shopping data 색인
similarity_data.json
[
{
"name": "고야드 플로트 백 숄더 쁘띠 플로 버킷백 PETIT 스페셜-그레이"
},
{
"name": "고야드 쁘띠플로 버킷백 PETITFLOT 스페셜 03098 10237403"
},
{
"name": "해외고야드 방돔백 패브릭 스트랩 VENDOME BAG 기본컬러 블랙브라운 VENDOMEBAGFABRI"
},
{
"name": "고야드 알핀 알팡 미니 백팩 스폐셜 컬러"
},
{
"name": "고야드 보잉 25 클러치 파우치 전"
},
{
"name": "고야드 클러치 세나 PM 스페셜-레드"
},
{
"name": "명품가죽끈 뉴고야드-엠보카멜 카멜 Q-H805"
},
{
"name": "고야드 세나 클러치 MGM SENAT 스페셜 03446 10237202"
}]인덱스 3개 준비
- index1 = tf * 2
- index2 = idf *2
- index3 = norm *2
index_name1 = "script-similarity-index1"
index_name2 = "script-similarity-index2"
index_name3 = "script-similarity-index3"
index 동일한 데이터 6736건 색인

script 구성
script1 = "double tf = Math.sqrt(doc.freq); double idf = Math.log((field.docCount+1.0)/(term.docFreq+1.0)) + 1.0; double norm = 1/Math.sqrt(doc.length); return query.boost * tf * idf * norm;"
script2 = "double tf = Math.sqrt(doc.freq); double idf = Math.log(((field.docCount * 2)+1.0)/(term.docFreq+1.0)) + 1.0; double norm = 1/Math.sqrt(doc.length); return query.boost * tf * idf * norm;"
script3 = "double tf = Math.sqrt(doc.freq); double idf = Math.log((field.docCount+1.0)/(term.docFreq+1.0)) + 1.0; double norm = 1/Math.sqrt(doc.length * 2); return query.boost * tf * idf * norm;"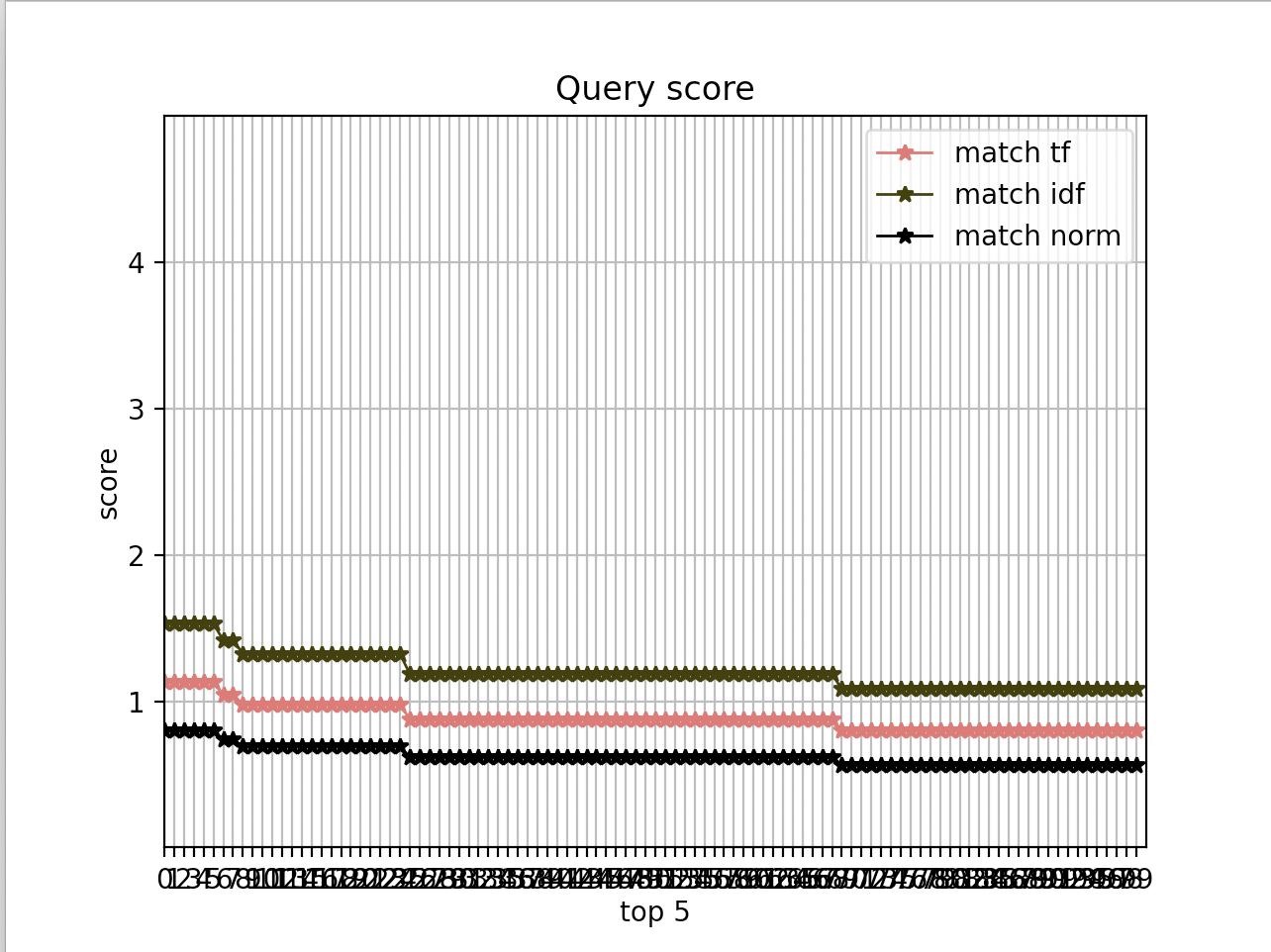
from elasticsearch import Elasticsearch
import pprint as ppr
import json
import math
import matplotlib.pyplot as plt
import numpy as np
index_name1 = "script-similarity-index1"
index_name2 = "script-similarity-index2"
index_name3 = "script-similarity-index3"
class EsAPI:
es = Elasticsearch(hosts="localhost", port=9200, http_auth=('elastic', 'dlengus')) # 객체 생성
@classmethod
def srvHealthCheck(cls):
health = cls.es.cluster.health()
print(health)
@classmethod
def allIndex(cls): # Elasticsearch에 있는 모든 Index 조회
print(cls.es.cat.indices())
@classmethod
def dataInsert(cls):
# ===============
# 데이터 삽입
# ===============
with open("/Users/doo/project/tf-embeddings/data/similarity_data.json", "r", encoding="utf-8") as fjson:
data = json.loads(fjson.read())
for n, i in enumerate(data):
doc = {
"name": i['name']
}
cls.es.index(index=index_name1, doc_type="_doc", id=n + 1, body=doc)
cls.es.index(index=index_name2, doc_type="_doc", id=n + 1, body=doc)
cls.es.index(index=index_name3, doc_type="_doc", id=n + 1, body=doc)
print(i['name'])
cls.es.indices.refresh(index=index_name1)
cls.es.indices.refresh(index=index_name2)
cls.es.indices.refresh(index=index_name3)
print("done.")
@classmethod
def searchResult(cls):
keyword = input("query : ")
SEARCH_SIZE=100
MAX_SCORE = 5
query1 = {
"size" : SEARCH_SIZE,
"query": {
"match": {
"name" : keyword
}
}
}
query2 = {
"size" : SEARCH_SIZE,
"query": {
"match": {
"name" : keyword
}
}
}
query3 = {
"size" : SEARCH_SIZE,
"query": {
"match": {
"name" : keyword
}
}
}
x = np.arange(0, SEARCH_SIZE, 1)
print(x)
y1 = EsAPI.searchScore(query1, index_name1)
print(y1)
y2 = EsAPI.searchScore(query2, index_name2)
print(y2)
y3 = EsAPI.searchScore(query3, index_name3)
print(y3)
plt.xlim([1, len(y1)]) # X축의 범위: [xmin, xmax]
plt.ylim([0, MAX_SCORE]) # Y축의 범위: [ymin, ymax]
plt.xlabel('top 5', labelpad=2)
plt.ylabel('score', labelpad=2)
plt.plot(x, y1, label='match tf', color='#e35f62', marker='*', linewidth=1)
plt.plot(x, y2, label='match idf', color='#333300', marker='*', linewidth=1)
plt.plot(x, y3, label='match norm', color='#000000', marker='*', linewidth=1)
plt.legend()
plt.title('Query score')
plt.xticks(x)
plt.yticks(np.arange(1, MAX_SCORE))
plt.grid(True)
plt.show()
@classmethod
def searchScore(cls, query, index_name):
response = cls.es.search(
index=index_name,
body=query
)
return [hit["_score"] for hit in response["hits"]["hits"]]
@classmethod
def createIndexSet(cls):
script1 = "double tf = Math.sqrt(doc.freq); double idf = Math.log((field.docCount+1.0)/(term.docFreq+1.0)) + 1.0; double norm = 1/Math.sqrt(doc.length); return query.boost * tf * idf * norm;"
EsAPI.createIndex(script1, index_name1)
script2 = "double tf = Math.sqrt(doc.freq); double idf = Math.log(((field.docCount * 2)+1.0)/(term.docFreq+1.0)) + 1.0; double norm = 1/Math.sqrt(doc.length); return query.boost * tf * idf * norm;"
EsAPI.createIndex(script2, index_name2)
script3 = "double tf = Math.sqrt(doc.freq); double idf = Math.log((field.docCount+1.0)/(term.docFreq+1.0)) + 1.0; double norm = 1/Math.sqrt(doc.length * 2); return query.boost * tf * idf * norm;"
EsAPI.createIndex(script3, index_name3)
@classmethod
def createIndex(cls, script, index_name):
cls.es.indices.create(
index=index_name,
body={
"settings": {
"number_of_replicas": 0,
"number_of_shards": 1,
"similarity": {
"scripted_tfidf": {
"type": "scripted",
"script": {
"source": script
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"similarity": "scripted_tfidf"
}
}
}
}
)
# EsAPI.createIndexSet()
# EsAPI.dataInsert()
EsAPI.searchResult()
반응형
'ElasticStack > Elasticsearch' 카테고리의 다른 글
| [es] script similarity test phase 2 (0) | 2022.07.03 |
|---|---|
| [es] sort - payload sort (0) | 2022.06.30 |
| [es] scripted similarity (0) | 2022.06.24 |
| [es] Similarity module (0) | 2022.06.24 |
| [es] Nested Query vs Object Query (0) | 2022.06.21 |