
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- Java
- Kafka
- Test
- API
- zip 암호화
- TensorFlow
- analyzer test
- springboot
- MySQL
- matplotlib
- Mac
- License
- zip 파일 암호화
- 파이썬
- Elasticsearch
- plugin
- aggregation
- high level client
- license delete
- docker
- 900gle
- flask
- Python
- sort
- query
- token filter test
- ELASTIC
- 차트
- aggs
- licence delete curl
Archives
- Today
- Total
개발잡부
[kibana 8] Kibana Maps 본문
반응형
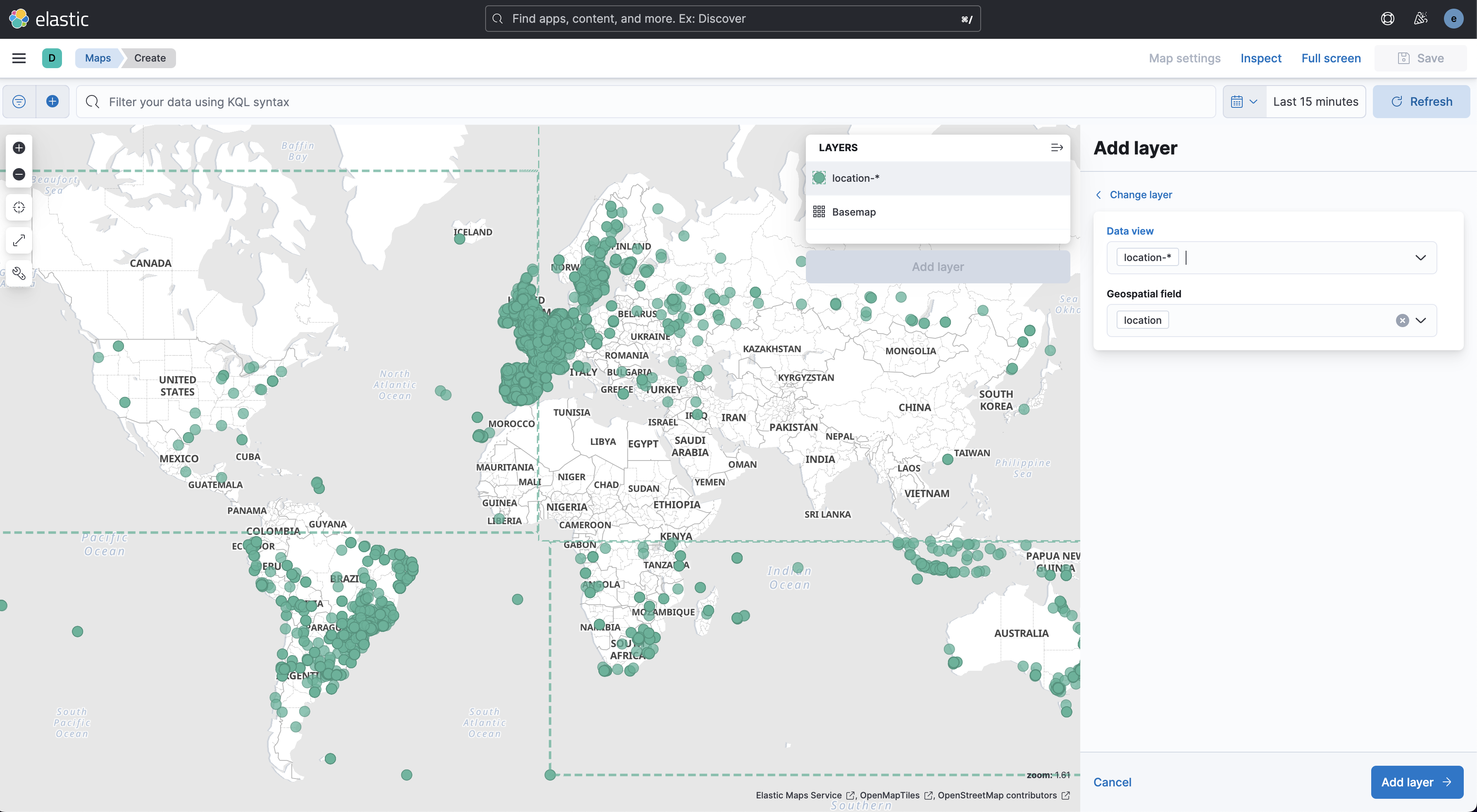
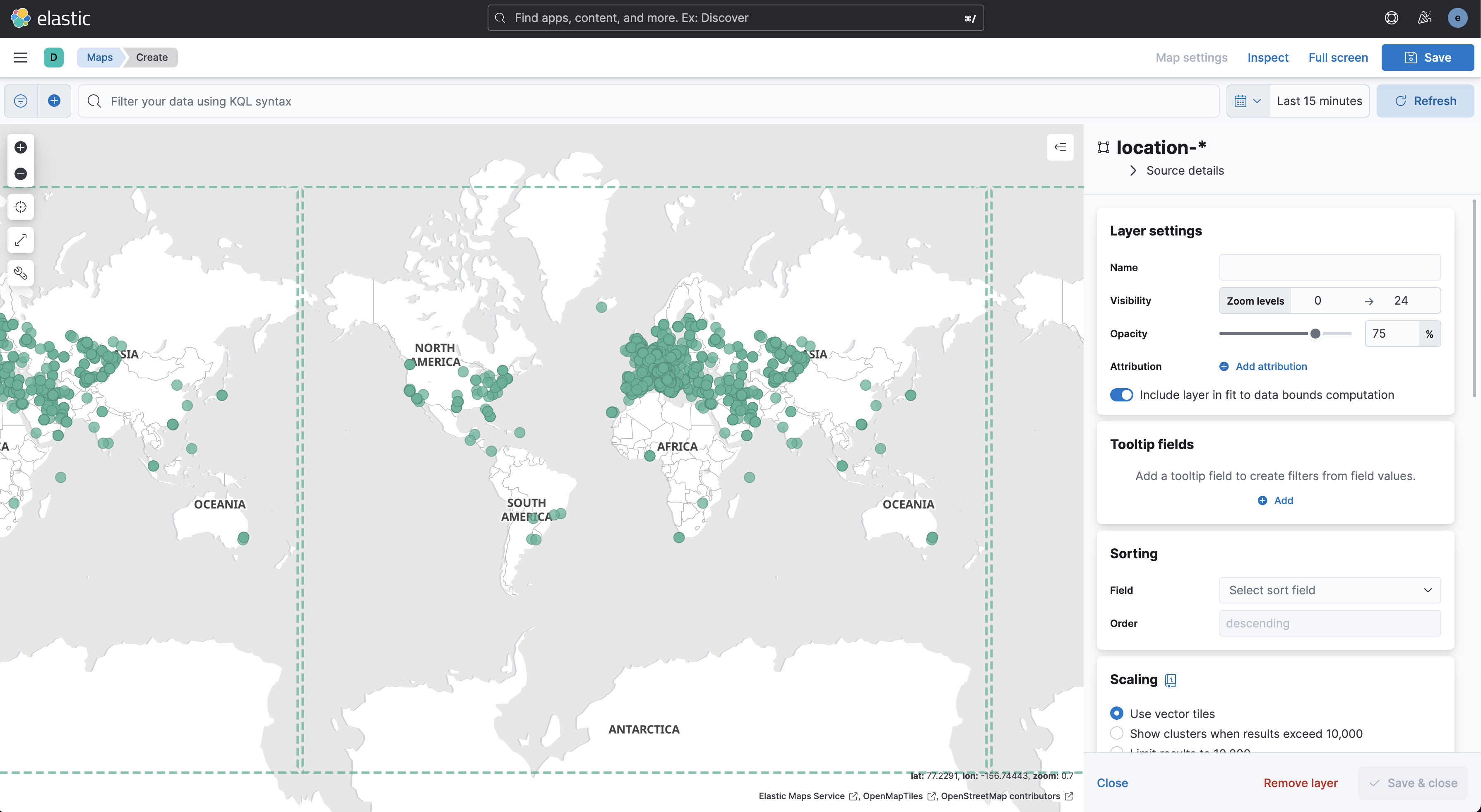
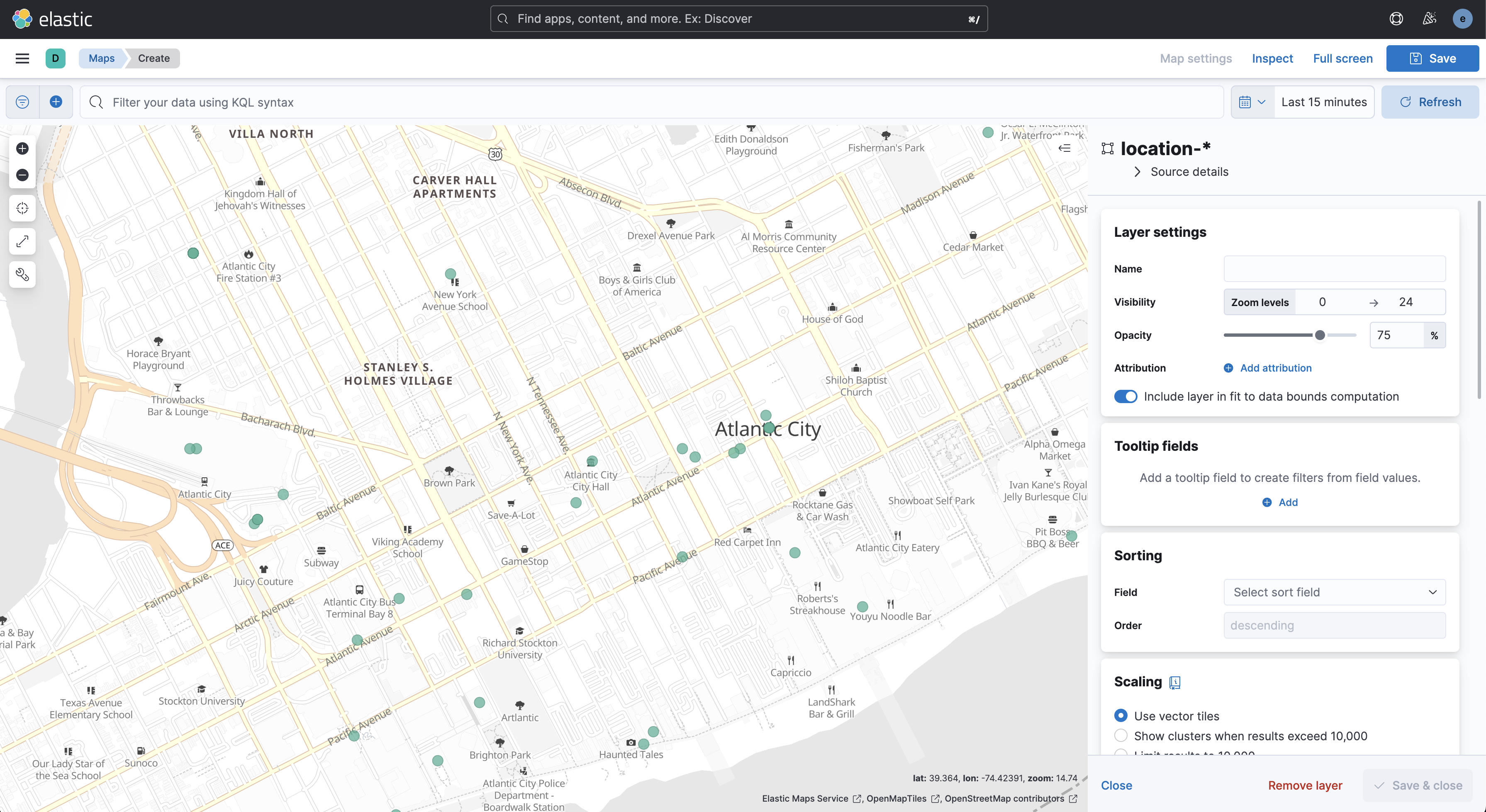
elastic stack 8.4.1 을 설치 후 kibana maps 가 있길래 한번 건들여봄
국가별 ip 와 위도 경도 정보가 있는 파일을 ES에 색인하고 maps 를 실행시켜서 확인해보았다.
색인 구조를 가지고 있는 index.json 파일
나중에 아이피도 테스트 해봐야 하니까 ip 정보는 ip type 타입으로 맵핑, location 정보는 geo_point 타입으로 맵핑 나머지는 주소정보니까 대충 keyword 타입으로 맵핑
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
},
"mappings": {
"dynamic": "true",
"_source": {
"enabled": "true"
},
"properties": {
"private_ip": {
"type": "ip"
},
"public_ip": {
"type": "ip"
},
"country_code": {
"type": "keyword"
},
"city": {
"type": "keyword"
},
"addr1": {
"type": "keyword"
},
"location": {
"type": "geo_point"
},
"no": {
"type": "keyword"
},
"country": {
"type": "keyword"
}
}
}
}
색인 파일은 put_data.py 재활용
# -*- coding: utf-8 -*-
import json
import csv
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
import tensorflow_hub as hub
import tensorflow_text
import kss, numpy
def is_number(x):
try:
# only integers and float converts safely
num = float(x)
return True
except ValueError as e: # not convertable to float
return False
##### INDEXING #####
def index_data():
print("Creating the '" + INDEX_NAME_A + "' index.")
client.indices.delete(index=INDEX_NAME_A, ignore=[404])
with open(INDEX_FILE_A) as index_file:
source = index_file.read().strip()
client.indices.create(index=INDEX_NAME_A, body=source)
csv_mapping_list = []
with open(DATA_FILE) as my_data:
csv_reader = csv.reader(my_data, delimiter=",")
line_count = 0
for line in csv_reader:
if line_count == 0:
header = line
else:
row_dict = {'private_ip': line[0], 'public_ip': line[1], 'country_code': line[2], 'city': line[3],
'addr1': line[4], 'location': {'lat':line[5], 'lon': line[6]}, 'no': line[7], 'country': line[8]}
if is_number(line[5]) and is_number(line[6]):
csv_mapping_list.append(row_dict)
line_count += 1
if line_count % BATCH_SIZE == 0:
index_batch_a(csv_mapping_list)
csv_mapping_list = []
print("Indexed {} documents.".format(line_count))
if csv_mapping_list:
index_batch_a(csv_mapping_list)
print("Indexed {} documents.".format(line_count))
client.indices.refresh(index=INDEX_NAME_A)
print("Done indexing.")
def index_batch_a(docs):
requests = []
for i, doc in enumerate(docs):
request = doc
request["_op_type"] = "index"
request["_index"] = INDEX_NAME_A
requests.append(request)
bulk(client, requests, pipeline='timestamp')
##### MAIN SCRIPT #####
if __name__ == '__main__':
INDEX_NAME_A = "location-index"
INDEX_FILE_A = "./data/location/index.json"
DATA_FILE = "./data/dbip-location-2016-01.csv"
BATCH_SIZE = 5000
client = Elasticsearch(http_auth=('elastic', 'dlengus'))
index_data()
print("Done.")csv 파싱하는데 geo_point 타입에 저장해야 하는 latitude, longitude 정보에 float 타입이 아닌 데이터가 들어와서 전체를 색인하는데 실패.. 했으나
float 을 검사하는 함수를 추가해서 해결
https://ldh-6019.tistory.com/405
[python] float check
def is_number(x): try: f = float(x) return True except ValueError as e: return False try: float(element) except ValueError: print "Not a float" check_float = isinstance(25.9, float)
ldh-6019.tistory.com
색인을 돌려보니 요렇네
사이즈 : 1GB
820만건 데이터

키바나 접속







반응형
Comments