
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- springboot
- aggregation
- 파이썬
- matplotlib
- plugin
- Java
- License
- aggs
- ELASTIC
- docker
- zip 파일 암호화
- Mac
- TensorFlow
- Python
- licence delete curl
- 900gle
- sort
- Elasticsearch
- API
- high level client
- query
- MySQL
- Test
- license delete
- analyzer test
- Kafka
- flask
- zip 암호화
- 차트
- token filter test
Archives
- Today
- Total
개발잡부
[es] N-gram tokenizer 본문
반응형
간만에 ES 테스트
N-gram tokenizer
우선 프로젝트로 이동
es8.6환경 만들어 놓은게 있으니 활용
cd /Users/doo/docker/es8.6.2
docker compose up -d --build아 역시나 이럴줄 ..
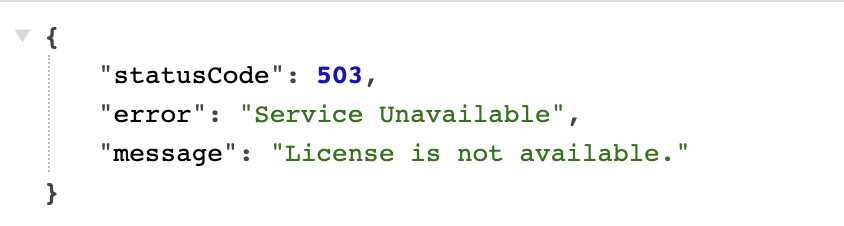
900gle es 로 변경 - es 7.15.1
cd /Users/doo/project/900gle/docker/elastic-stack
docker compose up -d --buildngram 토크나이저로 home 을 분해해 보면

아래와 같이 분해가 된다
{
"tokens" : [
{
"token" : "h",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "ho",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 1
},
{
"token" : "o",
"start_offset" : 1,
"end_offset" : 2,
"type" : "word",
"position" : 2
},
{
"token" : "om",
"start_offset" : 1,
"end_offset" : 3,
"type" : "word",
"position" : 3
},
{
"token" : "m",
"start_offset" : 2,
"end_offset" : 3,
"type" : "word",
"position" : 4
},
{
"token" : "me",
"start_offset" : 2,
"end_offset" : 4,
"type" : "word",
"position" : 5
},
{
"token" : "e",
"start_offset" : 3,
"end_offset" : 4,
"type" : "word",
"position" : 6
}
]
}
구성
ngram 매개변수
| min_gram | 그램의 최소 문자 길이입니다. 기본값은 입니다 1. |
| max_gram | 그램의 최대 문자 길이입니다. 기본값은 입니다 2. |
| token_chars | 토큰에 포함되어야 하는 문자 클래스입니다. Elasticsearch는 지정된 클래스에 속하지 않는 문자로 분할됩니다. 기본값은 [](모든 문자 유지)입니다. 문자 클래스는 다음 중 하나일 수 있습니다.
|
| custom_token_chars | 토큰의 일부로 취급되어야 하는 사용자 지정 문자입니다. 예를 들어 이것을 로 설정하면 +-_토크나이저가 더하기, 빼기 및 밑줄 기호를 토큰의 일부로 취급하게 됩니다. |
일반적으로 동일한 값으로 min_gram설정 하는 것이 좋습니다 . max_gram길이가 짧을수록 더 많은 문서가 일치하지만 일치 품질이 낮아집니다. 길이가 길수록 일치 항목이 더 구체적입니다. 트라이그램(길이 3)은 시작하기에 좋은 곳입니다.
인덱스 레벨 설정은 와 index.max_ngram_diff사이에 허용되는 최대 차이를 제어합니다 .max_grammin_gram
PUT doo_ngram
{
"settings": {
"analysis": {
"analyzer": {
"n_analyzer": {
"tokenizer": "n_tokenizer"
}
},
"tokenizer": {
"n_tokenizer": {
"type": "ngram",
"min_gram": 3,
"max_gram": 3,
"token_chars": [
"letter",
"digit"
]
}
}
}
}
}analyzer 확인
POST doo_ngram/_analyze
{
"analyzer": "n_analyzer",
"text": "homeplus doo"
}
결과
{
"tokens" : [
{
"token" : "hom",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "ome",
"start_offset" : 1,
"end_offset" : 4,
"type" : "word",
"position" : 1
},
{
"token" : "mep",
"start_offset" : 2,
"end_offset" : 5,
"type" : "word",
"position" : 2
},
{
"token" : "epl",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 3
},
{
"token" : "plu",
"start_offset" : 4,
"end_offset" : 7,
"type" : "word",
"position" : 4
},
{
"token" : "lus",
"start_offset" : 5,
"end_offset" : 8,
"type" : "word",
"position" : 5
},
{
"token" : "doo",
"start_offset" : 9,
"end_offset" : 12,
"type" : "word",
"position" : 6
}
]
}"오늘 점심 추천 메뉴: 파스타, 피자"
| 모델명 | 구현 결과 | |
| 1 | Unigram(N=1) | 오늘, 점심, 추천, 메뉴, 파스타, 피자 |
| 2 | Bigram(N=2) | 오늘 점심, 점심 추천, 추천 메뉴, 메뉴 파스타, 파스타 피자 |
| 3 | Trigram(N=3) | 오늘 점심 추천, 점심 추천 메뉴, 추천 메뉴 파스타, 메뉴 파스타 피자 |
| 4 | 4-gram(N=4) | 오늘 점심 추천 메뉴, 점심 추천 메뉴 파스타, 추천 메뉴 파스타 피자 |
반응형
'ElasticStack > Elasticsearch' 카테고리의 다른 글
| 신조어 추천 (0) | 2023.06.05 |
|---|---|
| [es] min_score (0) | 2023.05.16 |
| [es] python elasticsearch analyze test (0) | 2023.03.14 |
| [es]샤드 크기 조정 (0) | 2023.03.01 |
| [es] nested object sort (0) | 2023.01.17 |
'ElasticStack/Elasticsearch' Related Articles
more


Comments