
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- aggregation
- Python
- token filter test
- Java
- springboot
- TensorFlow
- Mac
- high level client
- flask
- license delete
- licence delete curl
- plugin
- aggs
- ELASTIC
- matplotlib
- 차트
- 900gle
- License
- docker
- analyzer test
- sort
- MySQL
- Kafka
- Test
- API
- query
- zip 파일 암호화
- zip 암호화
- Elasticsearch
- 파이썬
Archives
- Today
- Total
개발잡부
[tensorflow 2] Universal-sentence-encoder-multilingual 2 본문
Python/text embeddings
[tensorflow 2] Universal-sentence-encoder-multilingual 2
닉의네임 2022. 1. 12. 13:35반응형
universal-sentence-encoder-multilingual 2 (products)
상품정보로 테스트 해본다
아래 모듈을 테스트 한 결과가 기대와 서로 사맛디 아니하여 다른 모듈 테스트 - 다국어용이라고 함
https://tfhub.dev/google/universal-sentence-encoder/2
https://tfhub.dev/google/universal-sentence-encoder/44버전 테스트
https://ldh-6019.tistory.com/118?category=1043090
#가상환경 목록확인
conda info --envs
#가상환경 생성
conda create --name "text" python="3.7"
#가상환경 실행
conda activate text
pip install -r require.txt
인덱스는 지난번 테스트와 같은 구조로 생서한다. 512차원의 밀집백터 필드
index.json
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
},
"mappings": {
"dynamic": "true",
"_source": {
"enabled": "true"
},
"properties": {
"name": {
"type": "text"
},
"name_vector": {
"type": "dense_vector",
"dims": 512
},
"price": {
"type": "keyword"
},
"id": {
"type": "keyword"
}
}
}
}products.json 지난번과 같은 상품정보


2112개 상품 정보 색인
products_put.py
# -*- coding: utf-8 -*-
import json
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
import tensorflow_hub as hub
import tensorflow_text
import kss, numpy
##### INDEXING #####
def index_data():
print("Creating the 'korquad' index.")
client.indices.delete(index=INDEX_NAME, ignore=[404])
with open(INDEX_FILE) as index_file:
source = index_file.read().strip()
client.indices.create(index=INDEX_NAME, body=source)
count = 0
with open(DATA_FILE) as data_file:
for line in data_file:
line = line.strip()
json_data = json.loads(line)
docs = []
for j in json_data:
count += 1
docs.append(j)
if count % BATCH_SIZE == 0:
index_batch(docs)
docs = []
print("Indexed {} documents.".format(count))
if docs:
index_batch(docs)
print("Indexed {} documents.".format(count))
client.indices.refresh(index=INDEX_NAME)
print("Done indexing.")
def paragraph_index(paragraph):
avg_paragraph_vec = numpy.zeros((1, 512))
sent_count = 0
for sent in kss.split_sentences(paragraph):
avg_paragraph_vec += embed_text([sent])
sent_count += 1
avg_paragraph_vec /= sent_count
return avg_paragraph_vec.ravel(order='C')
def index_batch(docs):
titles = [doc["title"] for doc in docs]
title_vectors = embed_text(titles)
paragraph_vectors = [paragraph_index(doc["paragraph"]) for doc in docs]
requests = []
for i, doc in enumerate(docs):
request = doc
request["_op_type"] = "index"
request["_index"] = INDEX_NAME
request["title_vector"] = title_vectors[i]
request["paragraph_vector"] = paragraph_vectors[i]
requests.append(request)
bulk(client, requests)
##### EMBEDDING #####
def embed_text(input):
vectors = model(input)
return [vector.numpy().tolist() for vector in vectors]
##### MAIN SCRIPT #####
if __name__ == '__main__':
INDEX_NAME = "korquad"
INDEX_FILE = "./index.json"
DATA_FILE = "./KorQuAD_v1.0_train_convert.json"
BATCH_SIZE = 100
SEARCH_SIZE = 3
print("Downloading pre-trained embeddings from tensorflow hub...")
module_url = "https://tfhub.dev/google/universal-sentence-encoder-multilingual/3"
print("module %s loaded" % module_url)
model = hub.load(module_url)
# client = Elasticsearch()
client = Elasticsearch(http_auth=('elastic', 'datalake'))
index_data()
print("Done.")
search.py
# -*- coding: utf-8 -*-
import time
from elasticsearch import Elasticsearch
import tensorflow_hub as hub
import tensorflow_text
##### SEARCHING #####
def run_query_loop():
while True:
try:
handle_query()
except KeyboardInterrupt:
return
def handle_query():
query = input("Enter query: ")
embedding_start = time.time()
query_vector = embed_text([query])[0]
embedding_time = time.time() - embedding_start
script_query = {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "cosineSimilarity(params.query_vector, doc['name_vector']) + 1.0",
"params": {"query_vector": query_vector}
}
}
}
search_start = time.time()
response = client.search(
index=INDEX_NAME,
body={
"size": SEARCH_SIZE,
"query": script_query,
"_source": {"includes": ["name", "price"]}
}
)
search_time = time.time() - search_start
print()
print("{} total hits.".format(response["hits"]["total"]["value"]))
print("embedding time: {:.2f} ms".format(embedding_time * 1000))
print("search time: {:.2f} ms".format(search_time * 1000))
for hit in response["hits"]["hits"]:
print("id: {}, score: {}".format(hit["_id"], hit["_score"]))
print(hit["_source"])
print()
##### EMBEDDING #####
def embed_text(input):
vectors = model(input)
return [vector.numpy().tolist() for vector in vectors]
##### MAIN SCRIPT #####
if __name__ == '__main__':
INDEX_NAME = "products"
INDEX_FILE = "../data/posts/index.json"
SEARCH_SIZE = 3
print("Downloading pre-trained embeddings from tensorflow hub...")
module_url = "https://tfhub.dev/google/universal-sentence-encoder-multilingual/3"
print("module %s loaded" % module_url)
model = hub.load(module_url)
client = Elasticsearch(http_auth=('elastic', 'datalake'))
run_query_loop()
print("Done.")결과
Enter query: 실버 롤렉스
2112 total hits.
embedding time: 7.82 ms
search time: 9.78 ms
id: LrN-TH4BQC_QzfhZnchd, score: 1.7557327
{'price': 0, 'name': '롤렉스 메탈밴드시계 116710BLNR 실버'}
id: 5rN-TH4BQC_QzfhZpsgJ, score: 1.7504681
{'price': 13300000, 'name': '롤렉스 214270 실버'}
id: 1rN-TH4BQC_QzfhZpchC, score: 1.6863644
{'price': 18300000, 'name': '롤렉스 데이저스트41 126333'}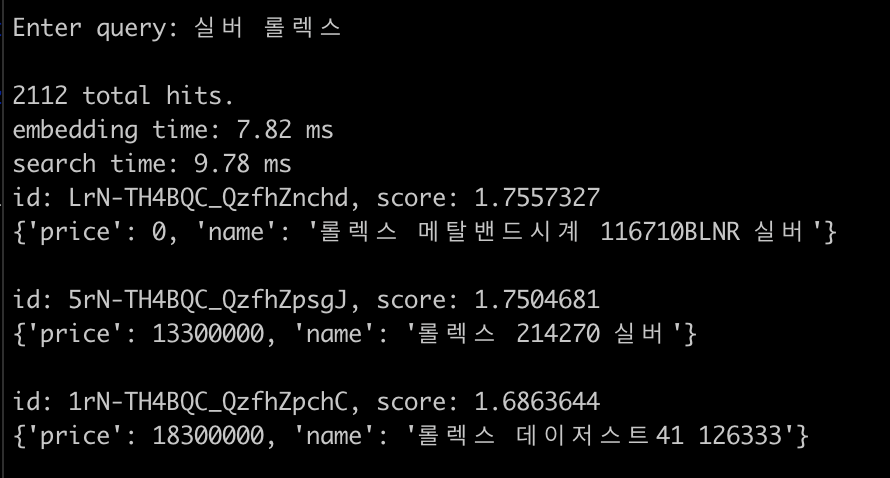
지난번 결과랑 비교하면 조금 나아진듯..하나..
음..
반응형
'Python > text embeddings' 카테고리의 다른 글
| [tensorflow 2]Universal-sentence-encoder-multilingual-large (0) | 2022.01.13 |
|---|---|
| [tensorflow 2] sentence encoder A/B test (0) | 2022.01.12 |
| [tensorflow 2] universal-sentence-encoder-multilingual (0) | 2022.01.11 |
| [tensorflow 2] tf-embeddings 한글버전 (0) | 2021.12.24 |
| [tensorflow]text-embeddings (0) | 2021.12.22 |
'Python/text embeddings' Related Articles
more



