
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
Tags
- Java
- high level client
- Mac
- ELASTIC
- query
- aggs
- aggregation
- springboot
- token filter test
- licence delete curl
- matplotlib
- API
- License
- docker
- Python
- 900gle
- license delete
- Kafka
- TensorFlow
- sort
- Test
- Elasticsearch
- 파이썬
- analyzer test
- plugin
- zip 암호화
- MySQL
- 차트
- flask
- zip 파일 암호화
Archives
- Today
- Total
개발잡부
[es] 검색쿼리에 랭킹을 적용해보자! 본문
반응형
나만의 랭킹 알고리즘 1단계

랭킹은 유사도값 x 가중치 필드 값 x 인기도 / 검색 필드값의 길이
하면.. 유사도가 높고 가중치와 인기도가 높은데 검색 필드값이 짧은 문서가 상위로 가는게 목적인데..
해보자
https://ldh-6019.tistory.com/181?category=1029507
[es] 검색쿼리를 만들어 보자
900gle shopping 을 java 로 만들었으니.. Tensorflow text embedding 은 python API 통해서 vector를 받아오는 구조로.. 아래와 같이 만들예정 우선 파이썬으로 테스트 #! The vector functions of the fo..
ldh-6019.tistory.com
위에서 만든걸 재활용
index_r.json
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 0
},
"mappings": {
"dynamic": "true",
"_source": {
"enabled": "true"
},
"properties": {
"name": {
"type": "text",
"fielddata": true //추가
},
"feature_vector": {
"type": "dense_vector",
"dims": 512
},
"price": {
"type": "keyword"
},
"id": {
"type": "keyword"
},
"category": {
"type": "text",
"fielddata": true //추가
},
"weight": {
"type": "float"
},
"populr": {
"type": "integer"
}
}
}
}색인
put_data.py
# -*- coding: utf-8 -*-
import json
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
import tensorflow_hub as hub
import tensorflow_text
import kss, numpy
##### INDEXING #####
def index_data():
print("Creating the '" + INDEX_NAME_R + "' index.")
client.indices.delete(index=INDEX_NAME_R, ignore=[404])
with open(INDEX_FILE) as index_file:
source = index_file.read().strip()
client.indices.create(index=INDEX_NAME_R, body=source)
count = 0
docs = []
with open(DATA_FILE) as data_file:
for line in data_file:
line = line.strip()
json_data = json.loads(line)
docs.append(json_data)
count += 1
if count % BATCH_SIZE == 0:
index_batch_a(docs)
docs = []
print("Indexed {} documents.".format(count))
if docs:
index_batch_a(docs)
print("Indexed {} documents.".format(count))
client.indices.refresh(index=INDEX_NAME_R)
print("Done indexing.")
def index_batch_a(docs):
name = [doc["name"] for doc in docs]
name_vectors = embed_text_a(name)
requests = []
for i, doc in enumerate(docs):
request = doc
request["_op_type"] = "index"
request["_index"] = INDEX_NAME_R
request["feature_vector"] = name_vectors[i]
request["weight"] = 0.1
request["populr"] = 1
requests.append(request)
bulk(client, requests)
##### EMBEDDING #####
def embed_text_a(input):
vectors = embed_a(input)
return [vector.numpy().tolist() for vector in vectors]
##### MAIN SCRIPT #####
if __name__ == '__main__':
INDEX_NAME_R = "products_r"
INDEX_FILE = "./data/products/index_r.json"
DATA_FILE = "./data/products/products.json"
BATCH_SIZE = 100
SEARCH_SIZE = 3
print("Downloading pre-trained embeddings from tensorflow hub...")
embed_a = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3")
client = Elasticsearch(http_auth=('elastic', 'dlengus'))
index_data()
print("Done.")이렇게 색인


검색을 해보자
아래의 쿼리를 실행해보니..
분모의 text field 의 length 값을 추출하지 못해서 에러가 나는데..
1. multi type 으로 맵핑해서 필드명.keyword.length
2. "fielddata": true
둘중하나로 처리해야 하는데.. 둘다 영.. 찝찝해서.. 일단 테스트는 해봐야 하니까 2번으로 처리
script_query = {
"function_score": {
"query": {
"multi_match": {
"query": query,
"fields": [
"name^5",
"category"
]
}
},
"functions": [
{
"script_score": {
"script": {
"source": "cosineSimilarity(params.query_vector, 'feature_vector') * doc['weight'].value * doc['populr'].value / doc['name'].length + doc['category'].length",
"params": {
"query_vector": query_vector
}
}
},
"weight": 1
}
]
}
}
query.py
# -*- coding: utf-8 -*-
import time
from elasticsearch import Elasticsearch
import tensorflow_hub as hub
import tensorflow_text
##### SEARCHING #####
def run_query_loop():
while True:
try:
handle_query()
except KeyboardInterrupt:
return
def handle_query():
query = input("Enter query: ")
embedding_start = time.time()
query_vector = embed_text([query])[0]
embedding_time = time.time() - embedding_start
script_query = {
"function_score": {
"query": {
"multi_match": {
"query": query,
"fields": [
"name^5",
"category"
]
}
},
"functions": [
{
"script_score": {
"script": {
"source": "cosineSimilarity(params.query_vector, 'feature_vector') * doc['weight'].value * doc['populr'].value / doc['name'].length + doc['category'].length",
"params": {
"query_vector": query_vector
}
}
},
"weight": 1
}
]
}
}
# script_query = {
# "function_score": {
# "query": {
# "multi_match": {
# "query": query,
# "fields": [
# "name^5",
# "category"
# ]
# }
# },
# "functions": [
# {
# "script_score": {
# "script": {
# "source": "cosineSimilarity(params.query_vector, doc['name_vector']) + 1.0",
# "params": {
# "query_vector": query_vector
# }
# }
# },
# "weight": 50
# },
# {
# "filter": { "match": { "name": query } },
# "random_score": {},
# "weight": 23
# }
# ]
# }
# }
search_start = time.time()
response = client.search(
index=INDEX_NAME,
body={
"size": SEARCH_SIZE,
"query": script_query,
"_source": {"includes": ["name", "category"]}
}
)
search_time = time.time() - search_start
print()
print("{} total hits.".format(response["hits"]["total"]["value"]))
print("embedding time: {:.2f} ms".format(embedding_time * 1000))
print("search time: {:.2f} ms".format(search_time * 1000))
for hit in response["hits"]["hits"]:
print("id: {}, score: {}".format(hit["_id"], hit["_score"]))
print(hit["_source"])
print()
##### EMBEDDING #####
def embed_text(input):
vectors = model(input)
return [vector.numpy().tolist() for vector in vectors]
##### MAIN SCRIPT #####
if __name__ == '__main__':
INDEX_NAME = "products_r"
SEARCH_SIZE = 3
print("Downloading pre-trained embeddings from tensorflow hub...")
model = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3")
client = Elasticsearch(http_auth=('elastic', 'dlengus'))
run_query_loop()
print("Done.")
검색어 : 나이키 우먼스 러닝화
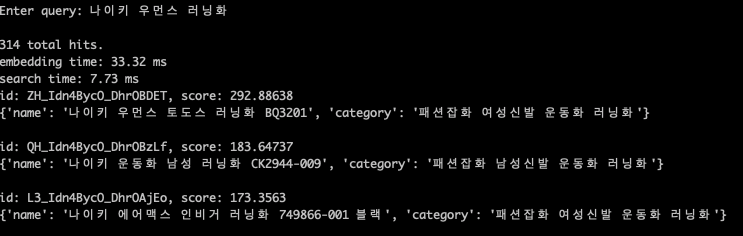
스코어가 이긔 뭐꼬..
1. 스코어 max 1 로 수정
2. 스코어 계산확인
3. 형태소 분석기 넣고 field 길이 확인
4. fielddata 이슈확인
반응형
'ElasticStack > Elasticsearch' 카테고리의 다른 글
| [es] 검색결과 비교 - score (0) | 2022.01.28 |
|---|---|
| [es] 검색결과를 검증해보자 (0) | 2022.01.21 |
| [es] 검색쿼리를 만들어 보자 (0) | 2022.01.15 |
| [es] Bool Query (0) | 2022.01.10 |
| [es] intervals query (0) | 2022.01.06 |
'ElasticStack/Elasticsearch' Related Articles
more


