
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Mac
- aggregation
- sort
- License
- API
- Test
- Java
- analyzer test
- docker
- zip 파일 암호화
- license delete
- Elasticsearch
- zip 암호화
- 차트
- token filter test
- matplotlib
- flask
- ELASTIC
- high level client
- 900gle
- TensorFlow
- 파이썬
- query
- MySQL
- aggs
- springboot
- plugin
- Python
- licence delete curl
- Kafka
- Today
- Total
목록전체 글 (460)
개발잡부
 [es] Warm up global ordinals
[es] Warm up global ordinals
전역 서수는 집계 성능을 최적화하는 데 사용되는 데이터 구조입니다. 이는 느리게 계산되어 필드 데이터 캐시의 일부로 JVM 힙에 저장됩니다. 버킷팅 집계에 많이 사용되는 필드의 경우 요청을 수신하기 전에 Elasticsearch에 전역 서수를 구성하고 캐시하도록 지시할 수 있습니다. 힙 사용량이 증가하고 새로 고침 시간이 더 오래 걸릴 수 있으므로 이 작업은 신중하게 수행해야 합니다. 이 옵션은 Eager 전역 서수 매핑 매개변수를 설정하여 기존 매핑에서 동적으로 업데이트될 수 있습니다. 맵핑 옵션 PUT index { "mappings": { "properties": { "foo": { "type": "keyword", "eager_global_ordinals": true } } } } 테스트 해보자 ..
검색 속도 조정 파일 시스템 캐시에 메모리 제공 더 빠른 하드웨어 사용 문서 모델링 가능한 한 적은 수의 필드를 검색 사전 색인 데이터 매핑 식별자를 키워드로 고려 스크립트 피하기 반올림된 날짜 검색 읽기 전용 인덱스 강제 병합 글로벌 서수 워밍업 색인 정렬을 사용하여 접속사 속도를 높임 기본 설정을 사용하여 캐시 활용도 최적화 복제본은 처리량에 도움이 될 수 있지만 항상 그런 것은 아님 회사에서 성능 이슈를 제기했다. elasticsearch 의 캐싱을 정리하려고 하는데 쿼리속도가 문제가 아닌걸 알지만 우선 es 레벨에서 캐싱으로 처리할 수 있는 부분을 정리 우선 속도에 영향을 미치는 부분은 The more fields a query_string or multi_match query targets, t..
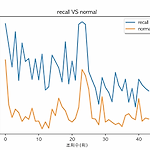 [matplotlib] 재현율 개선 쿼리와 일반쿼리 응답시간 비교
[matplotlib] 재현율 개선 쿼리와 일반쿼리 응답시간 비교
# -*- coding: utf-8 -*- import time import json import requests import ssl import urllib3 from ssl import create_default_context import matplotlib.pyplot as plt from matplotlib.collections import EventCollection import numpy as np from time import sleep plt.rcParams['font.family'] = 'AppleGothic' print(ssl.OPENSSL_VERSION) urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) def c..
 [python] DB data to json
[python] DB data to json
Database 를 조회 하여 json 파일을 만들어 보자 왜만드냐 하면 내 컴터성능이.. 찌글하여.. container 를 여러개 띄우기가 부담스러워서.. MySql 컨테이너는 DB 데이터를 조회할때만 띄우고 json 파일로 만들어서 파일을 색인 하는 방향으로 테스트를 진행 프로젝트 경로로 이동 /Users/doo/project/tf-embeddings/db 가상환경 실행 conda activate doo 파일 실행 python db_select_extract_json.py 결과 파일 생성 db_select_extract_json.py # -*- coding: utf-8 -*- import json import pymysql con = pymysql.connect(host='localhost', use..
 [MySql] MySQLWorkbench EER diagram 그리기
[MySql] MySQLWorkbench EER diagram 그리기
ERD ' Entity Relationship Diagram ' 흔히 E-R 다이어그램이라고 ERD 라고 줄여 부르기도 한다. '존재하고 있는 것(Entity)들의 관계(Relationship)을 나타낸 도표(Diagram)' 이다. workbench 에서 생성된 테이블로 ERD 를 그릴 수 있다. 접속하고 저 집 아이콘은 누르면 다음과 같은 화면이 보이는데 좌측 그림중에 ERD 비슷하게 생긴걸 눌러보자 그럼 Models 라는 타이틀이 나오는데 ' > ' 이렇게 생긴 버튼을 누르며 메뉴 두개가 나온다 Database 에 생성되어 있는 테이블로 ERD를 그릴꺼니까 위에 메뉴 선택 7단계을 거치면 그릴수 있는데 1. Connection Options - Database 접속정보 확인 2. Connect..
 [es] script query
[es] script query
불용어 (stopword) 필터를 사용해 analyzer 에서 불용어를 걸러낼 수는 있지만.. 이 no result 케이스에서 불용어때문에 걸러진건지 실제 true 인 데이터가 없는건지 알아내야 한다.. 왜냐..면 이 케이스에서 확장검색이 들어가야 하는데 이 확장검색이란 놈이 operator 가 or 이기때문에 조합형 불용어 에서는 정밀도가 떨어지는 검색결과가 나오게 되어 이 케이스를 없애달라는.. 원하는건 불용어를 포함한 검색어 일때 no result 처리 주의할점! 은 스크립트를 사용하면 검색속도가 느려질 수 있다. 암튼.. 일단 만들어 보자 es 는 8.8.1 버전에서 키바나와 es 만 실행 #내 로컬 경로 cd /Users/doo/docker/es8.8.1 docker compose es kiba..
GET _analyze { "text": "The quick brown fox jumps over the lazy dog", "analyzer": "snowball" } GET _analyze { "text": "The quick brown fox jumps over the lazy dog", "tokenizer": "homeplus_tokenizer", "filter": [ "lowercase", "stop", "snowball" ] }
 Cannot invoke "org.springframework.web.servlet.mvc.condition.PatternsRequestCondition.toString()"
Cannot invoke "org.springframework.web.servlet.mvc.condition.PatternsRequestCondition.toString()"
망할 스웨거 Cannot invoke "org.springframework.web.servlet.mvc.condition.PatternsRequestCondition.toString()" 원인은 spring boot 2.6.0부터 요청 경로를 ControllerHandler에 매칭시키기 위한 전략의 기본값이 ant_path_matcher 전략 -> path_pattern_parser 전략으로 변경되었기 때문 일단 해결 방법 spring: mvc: pathmatch: matching-strategy: ant_path_matcher 2.5.x 이하로 버전을 낮추라고 하는데 낮춰도 안됨 // https://mvnrepository.com/artifact/io.springfox/springfox-swagger2..
Java의 CompletableFuture에서 get()과 join() 메소드는 모두 완료된 CompletableFuture의 결과를 반환 get() join() interrupt O X interrupt 발생 InterruptedException 인터럽트 차단 Exception ExecutionException UncheckedExecutionException get() 메소드는 java.util.concurrent.Future 인터페이스에 정의되어 있으므로 이 인터페이스를 구현하는 다른 클래스와 호환 가능하지만, join() 메소드는 CompletableFuture 클래스에만 특화되어 있기 때문에 CompletableFuture와만 사용할 수 있다 일반적으로 CompletableFuture을 다룰 때..
 [es8] nori analyzer
[es8] nori analyzer
nori 형태소분석기의 사전파일 테스트 프로젝트 경로 /Users/doo/docker/es8.8.1 프로젝트를 활용할 예정 docker-compose.yml 파일을 열어보면 900gle 에서 쓰고있는 컨테이너들이 잔뜩 들어 있다.. pc 가 성능이 좋았으면 다돌려도 상관없는데.. 내껀 아니라 es, kibana 를 제거한 .yml 파일 생성 docker-compose.yml version: '3.7' services: # The 'setup' service runs a one-off script which initializes the # 'logstash_internal' and 'kibana_system' users inside Elasticsearch with the # values of the pa..