
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- MySQL
- license delete
- token filter test
- Java
- high level client
- API
- TensorFlow
- ELASTIC
- 파이썬
- matplotlib
- License
- aggs
- sort
- licence delete curl
- Elasticsearch
- Mac
- Test
- analyzer test
- zip 파일 암호화
- docker
- springboot
- 차트
- query
- Kafka
- 900gle
- plugin
- flask
- zip 암호화
- Python
- aggregation
- Today
- Total
목록분류 전체보기 (475)
개발잡부
 [java] API - cache method
[java] API - cache method
검색결과중 일부 메소드에서 처리하는 데이터 들만 캐싱해야하는 상황.. 일단 구현해보자 https://father-lys.tistory.com/42 에서 세팅한 redis 정보를 활용 우선 컨드롤러 생성 CacheService 의 getCaches 를 호출 package com.doo.aqqle.controller; import com.doo.aqqle.model.CommonResult; import com.doo.aqqle.service.CacheService; import io.swagger.annotations.Api; import io.swagger.annotations.ApiOperation; import io.swagger.annotations.ApiParam; import lombok.Requ..
 [java] API - redis cache
[java] API - redis cache
지난시간 elasticsearch 의 file system cache 를 사용해서 성능을 올려보았는데 https://father-lys.tistory.com/40 [java] API - file system cache (request cache) API 를 만들고 응답시간을 측정해서 최적의 성능을 만들어 보자 일단 제물이 될 index 820만건의 location-index 일단 aqqle 의 shop API 를 응용해서 후다닥 만들어 보자. 복붙해서 이름만 바꾸니까 1분 미 father-lys.tistory.com 캐싱하면 redis 니까 함 넣어보잣 우선 redis 설치 https://father-lys.tistory.com/41 그리고 aqqle api 에 redis 설정 1. build.gradl..
 [java] API - file system cache (request cache)
[java] API - file system cache (request cache)
API 를 만들고 응답시간을 측정해서 최적의 성능을 만들어 보자 일단 제물이 될 index 820만건의 location-index 일단 aqqle 의 shop API 를 응용해서 후다닥 만들어 보자. 복붙해서 이름만 바꾸니까 1분 미만 컷 지금은 bool > filter > term 쿼리로 조회하니 응답속도가 빠르다. 일단 이 상태에서 리소스 사용과 응답속도를 측정해보잣 캐싱이 안되고 있지만 너무 빠르다 일단 지난 캐시 테스트와 같은 구조로 multi_match 쿼리 와 count집계(aggs) 를 두번 추가 전체쿼리 더보기 { "size":100, "query":{ "bool":{ "must":[ { "multi_match":{ "query":"country_code", "fields":[ "CO^1...
 [es] elasticsearch cache 모니터링 (query_cache, request_cache)
[es] elasticsearch cache 모니터링 (query_cache, request_cache)
검색 결과 리스팅은 Query Cache에, 검색 결과에 대한 집계 는 Request Cache 에 저장 된다 그렇다면 둘다 확인해서 multi_match + aggs 의 결과가 어디에 캐싱된건지 확인 GET /location-index/_stats/query_cache?human { "_shards": { "total": 2, "successful": 2, "failed": 0 }, "_all": { "primaries": { "query_cache": { "memory_size": "0b", "memory_size_in_bytes": 0, "total_count": 0, "hit_count": 0, "miss_count": 0, "cache_size": 0, "cache_count": 0, "evic..
 [es] file system cache 를 이용한..
[es] file system cache 를 이용한..
file system cache 를 이용한.. 꼼수를 부려보자 기존쿼리 + AGGS 를 사용하는데 file system cache 를 이용할 수 가 없다. 왜냐..면 size 가 0이 될 수 없는 상황.. 그래서 AGGS size 0을 먼저 실행하고 그다음 검색쿼리를 실행하면 캐싱을 이용하지 않을까 하는 생각이 있는데 테스트를 해보자 location 정보를 색인할 예정이고 "country_code": { "type": "keyword" }, "city": { "type": "keyword" }, city 를 집계하고 country code 를 쿼리한다. flowchart 이게 가능한가? aggs name 으로 캐시가 생성되면 가능할꺼 같기도 한데.. aggs 결과를 쿼리결과와 합치지 않아도 된다면 후 처..
 [es] Warm up global ordinals
[es] Warm up global ordinals
전역 서수는 집계 성능을 최적화하는 데 사용되는 데이터 구조입니다. 이는 느리게 계산되어 필드 데이터 캐시의 일부로 JVM 힙에 저장됩니다. 버킷팅 집계에 많이 사용되는 필드의 경우 요청을 수신하기 전에 Elasticsearch에 전역 서수를 구성하고 캐시하도록 지시할 수 있습니다. 힙 사용량이 증가하고 새로 고침 시간이 더 오래 걸릴 수 있으므로 이 작업은 신중하게 수행해야 합니다. 이 옵션은 Eager 전역 서수 매핑 매개변수를 설정하여 기존 매핑에서 동적으로 업데이트될 수 있습니다. 맵핑 옵션 PUT index { "mappings": { "properties": { "foo": { "type": "keyword", "eager_global_ordinals": true } } } } 테스트 해보자 ..
검색 속도 조정 파일 시스템 캐시에 메모리 제공 더 빠른 하드웨어 사용 문서 모델링 가능한 한 적은 수의 필드를 검색 사전 색인 데이터 매핑 식별자를 키워드로 고려 스크립트 피하기 반올림된 날짜 검색 읽기 전용 인덱스 강제 병합 글로벌 서수 워밍업 색인 정렬을 사용하여 접속사 속도를 높임 기본 설정을 사용하여 캐시 활용도 최적화 복제본은 처리량에 도움이 될 수 있지만 항상 그런 것은 아님 회사에서 성능 이슈를 제기했다. elasticsearch 의 캐싱을 정리하려고 하는데 쿼리속도가 문제가 아닌걸 알지만 우선 es 레벨에서 캐싱으로 처리할 수 있는 부분을 정리 우선 속도에 영향을 미치는 부분은 The more fields a query_string or multi_match query targets, t..
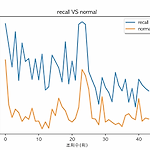 [matplotlib] 재현율 개선 쿼리와 일반쿼리 응답시간 비교
[matplotlib] 재현율 개선 쿼리와 일반쿼리 응답시간 비교
# -*- coding: utf-8 -*- import time import json import requests import ssl import urllib3 from ssl import create_default_context import matplotlib.pyplot as plt from matplotlib.collections import EventCollection import numpy as np from time import sleep plt.rcParams['font.family'] = 'AppleGothic' print(ssl.OPENSSL_VERSION) urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) def c..
 [python] DB data to json
[python] DB data to json
Database 를 조회 하여 json 파일을 만들어 보자 왜만드냐 하면 내 컴터성능이.. 찌글하여.. container 를 여러개 띄우기가 부담스러워서.. MySql 컨테이너는 DB 데이터를 조회할때만 띄우고 json 파일로 만들어서 파일을 색인 하는 방향으로 테스트를 진행 프로젝트 경로로 이동 /Users/doo/project/tf-embeddings/db 가상환경 실행 conda activate doo 파일 실행 python db_select_extract_json.py 결과 파일 생성 db_select_extract_json.py # -*- coding: utf-8 -*- import json import pymysql con = pymysql.connect(host='localhost', use..
 [MySql] MySQLWorkbench EER diagram 그리기
[MySql] MySQLWorkbench EER diagram 그리기
ERD ' Entity Relationship Diagram ' 흔히 E-R 다이어그램이라고 ERD 라고 줄여 부르기도 한다. '존재하고 있는 것(Entity)들의 관계(Relationship)을 나타낸 도표(Diagram)' 이다. workbench 에서 생성된 테이블로 ERD 를 그릴 수 있다. 접속하고 저 집 아이콘은 누르면 다음과 같은 화면이 보이는데 좌측 그림중에 ERD 비슷하게 생긴걸 눌러보자 그럼 Models 라는 타이틀이 나오는데 ' > ' 이렇게 생긴 버튼을 누르며 메뉴 두개가 나온다 Database 에 생성되어 있는 테이블로 ERD를 그릴꺼니까 위에 메뉴 선택 7단계을 거치면 그릴수 있는데 1. Connection Options - Database 접속정보 확인 2. Connect..